Cualquiera que haya interactuado un par de veces con un modelo de lenguaje grande (LLM) habrá notado un comportamiento curioso: le haces la misma pregunta exacta en momentos diferentes, y las respuestas varían. A veces cambia el orden de las palabras, a veces el tono, y en algunas ocasiones, el enfoque conceptual es completamente distinto. ¿Por qué ocurre esto?
Para quienes venimos del desarrollo de software tradicional, donde una base de datos o una función matemática siempre devuelve el mismo resultado ante los mismos parámetros de entrada, este comportamiento puede parecer un error. Sin embargo, no es un bug; es la característica fundamental sobre la que se construye la inteligencia artificial moderna. Los modelos de IA actuales son, por definición, probabilísticos.
El dado estadístico de los modelos lingüísticos
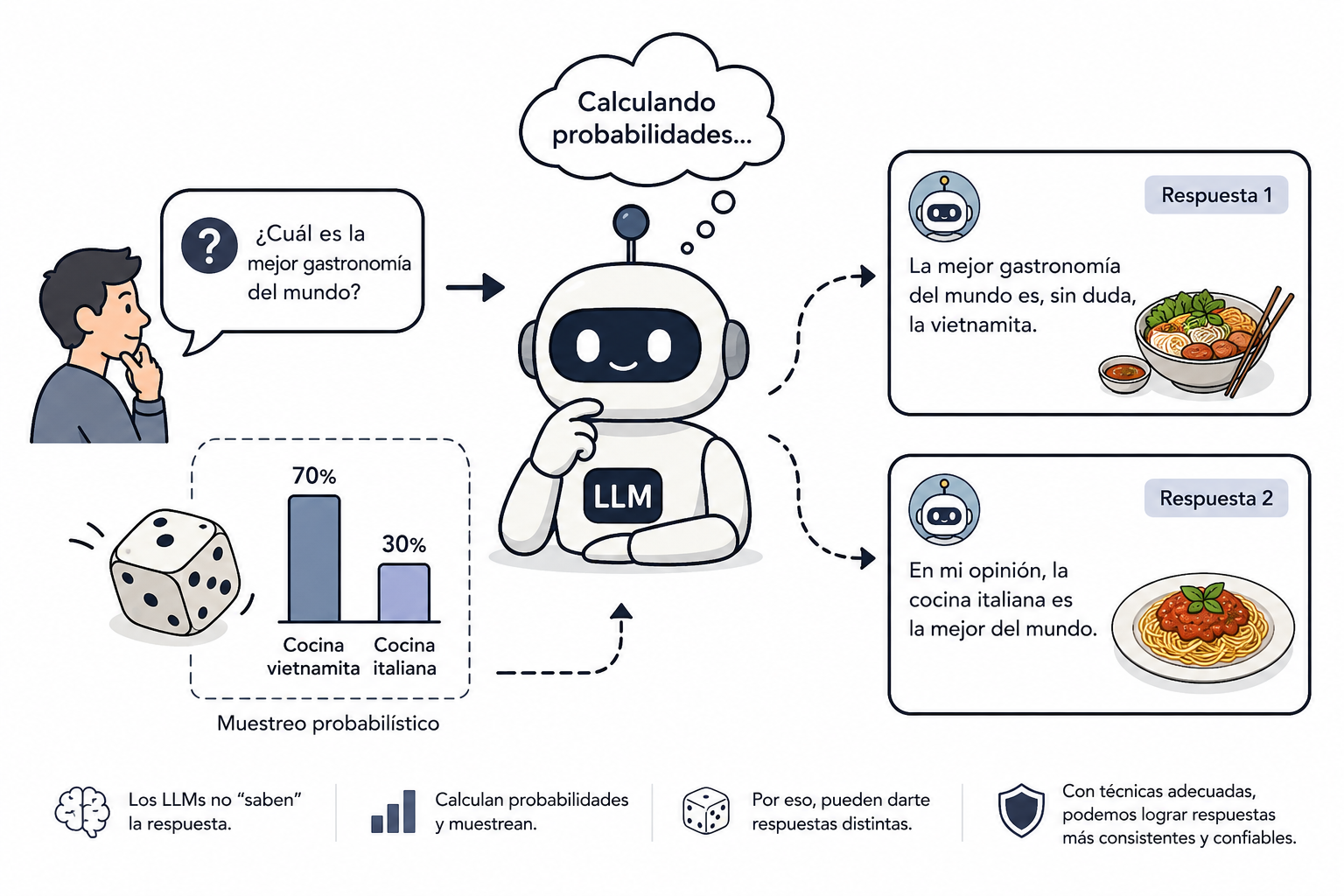
En su libro AI Engineering, Chip Huyen ilustra este concepto con una analogía muy directa sobre cómo los modelos seleccionan sus respuestas. Imagina que le preguntas a un amigo cuál es la mejor gastronomía del mundo. Si se lo preguntas dos veces con un minuto de diferencia, lo lógico es que te responda lo mismo en ambas ocasiones. Su criterio es estable.
Con un LLM, el proceso interno es radicalmente distinto. El modelo no “sabe” qué comida es la mejor en el sentido humano; calcula probabilidades estadísticas de éxito textual basándose en su entrenamiento. Huyen lo explica así: si un modelo de IA estima que la cocina vietnamita tiene un 70% de probabilidad de ser la mejor del mundo y la cocina italiana un 30%, no te dará una respuesta única y fija. Responderá “cocina vietnamita” el 70% de las veces y “cocina italiana” el 30% restante.
Lo opuesto a este comportamiento es un sistema determinista, donde el resultado final se calcula de forma exacta y sin variaciones aleatorias. La IA actual opera en el espectro opuesto, seleccionando la siguiente palabra (o token) mediante un muestreo probabilístico continuo.
Inconsistencia y alucinaciones: El costo colateral
Esta flexibilidad matemática es el motor de su creatividad y capacidad de adaptación, permitiéndole redactar correos, resumir textos complejos o estructurar código de mil formas distintas. No obstante, cuando necesitamos consistencia técnica en entornos de producción, esta misma naturaleza se convierte en un desafío crítico que introduce dos problemas principales:
- Inconsistencia: El envío del mismo prompt puede generar variaciones estructurales muy marcadas, lo que dificulta la automatización de procesos donde los sistemas internos esperan formatos de salida predecibles.
- Alucinaciones: Si los datos de entrenamiento contienen información errónea o satírica (por ejemplo, un ensayo en internet que asegure que todos los presidentes de EE. UU. son extraterrestres), el modelo calculará la probabilidad estadística de esos términos. Al generar texto, podría entrelazar esos datos falsos de forma tan coherente y fluida que la respuesta parecerá lógica y verdadera, aun cuando carezca por completo de sustento real. El modelo simplemente une los eslabones probabilísticos más viables en ese microsegundo.
Domesticando la aleatoriedad: Parámetros de control esenciales
Cuando pasamos de experimentar en una interfaz de chat a integrar modelos de lenguaje en la infraestructura real de una empresa, la predictibilidad se vuelve obligatoria. No podemos permitir que un agente automatizado o un pipeline de datos invente información. Por suerte, disponemos de herramientas de control para mitigar la dispersión matemática:
- Controlar la Temperatura: Es el parámetro que regula el grado de aleatoriedad del modelo. Una temperatura cercana a 0 reduce la variabilidad drásticamente. El modelo se vuelve casi determinista, eligiendo siempre el token con mayor probabilidad estadística (ideal para generar código, extraer entidades o interpretar JSON). Una temperatura cercana a 1 distribuye las oportunidades entre tokens menos probables, inyectando creatividad y variedad al texto (ideal para brainstorming o copywriting).
- Parámetro Top-P (Nucleus Sampling): En lugar de evaluar todo el vocabulario posible, restringe las opciones del modelo a un “núcleo” de palabras que concentran el mayor peso estadístico. Si configurás un Top-P de 0.90, la IA solo considerará el grupo de palabras cuyas probabilidades acumuladas sumen el 90%, descartando por completo opciones marginales o demasiado raras.
- Arquitecturas RAG (Generación Aumentada por Recuperación): Para solucionar las alucinaciones de raíz, la estrategia actual no depende de la “memoria” del modelo. Mediante RAG, interceptamos la consulta, buscamos datos reales y validados en los repositorios o bases de datos de la empresa, y se los inyectamos directamente en el contexto del prompt como la única fuente de verdad permitida. Al delimitar estrictamente el terreno de juego, el motor estadístico del LLM se limita a procesar la información real proporcionada, reduciendo el riesgo de inventar datos a prácticamente cero.
- Exigir fuentes citadas en las respuestas: Esta es una técnica que implica solicitar al LLM que cite sus fuentes. No elimina la alucinación, pero si es un buen guarda raíl para evitar que se masifique en nuestras respuestas (por esto vemos que cada vez más los modelos citan en sus respuestas).
Pensar en flujos probabilísticos
Integrar IA en la arquitectura de operaciones actual exige un cambio de mentalidad. No estamos interactuando con bases de datos estáticas; estamos gestionando motores estadísticos masivos. El secreto para construir sistemas empresariales robustos no radica en intentar cambiar la esencia probabilística de la IA, sino en diseñar los contenedores, contextos y parámetros adecuados para guiarla y aprovechar su máximo potencial sin sorpresas.
¿Necesitas asistencia para integrar IA a tu flujo de trabajo?
En D2B diseñamos agentes inteligentes que conversan directamente con tus datos, automatizan procesos críticos y se integran de forma segura con tu infraestructura tecnológica. Además, escalamos arquitecturas Cloud preparadas para IA moderna, asegurando soluciones estables, eficientes y listas para crecer junto a tu operación. Conversemos sobre cómo llevar tu empresa al siguiente nivel de automatización e inteligencia operativa.